


Generalizing rivers and lakes - Openstreetmap data processing
In the first part of this text i talked about the general problems of rendering rivers and lakes in a map. Here i will deal more specifically with the problems of processing the Openstreetmap data.
Processing the Openstreetmap data
As i have described in my text about the data quality the water data in OSM is somewhat limited. It can essentially be summarized this way: The Openstreetmap water data can be used to render the waterbodies in a plain way like in the main slippy map but not for much else.
Generalizing the Openstreetmap waterbody data is challenging in two different ways: First the data is very variable in quality and completeness as described in my text on the data quality and second the amounts of data are huge. For comparison: While the coastline of the whole earth is a 3GB osm file the water areas are are about 28GB and the waterways about 18GB. This data is much concentrated in the densely mapped areas of central Europe, North America and Japan. Much of this data could be omitted when generalizing for lower zoom level maps since it consists of very small features that would not affect the result anyway. But simply dropping features based on their size does not work since the large and important waterbodies often contain smaller features like way segments with just a few nodes.
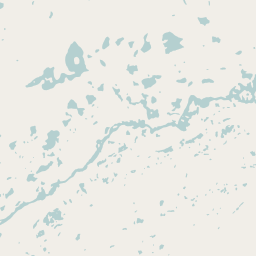
The approach i took essentially boils down to actually rendering the data into a land-water mask and using this as a basis for further processing. Rendering into a raster map is what the OSM data is most suited for as said above and as with the coastlines a raster representation is a good basis for further generalization steps. In case of the coastlines initial rasterization at zoom=9 was sufficient to catch most topological features in the data.

|
|
| rendering example z=9 | rendering example z=12 |
In case of the waterbodies this is not sufficient, the major problem here are thin water areas representing riverbanks without a centerline which do not form a continuous water area in the raster representation. I developed two methods to deal with this: The first is to fix these problems superficially in the full vector data before performing the rasterization at z=9. This works fairly reliably but scales quite badly, in other words it is prohibitively slow when there is a high data density across a larger area. The second method directly rasterizes at z=12 which is sufficient to reliably represent most of the waterbody topology in Openstreetmap in the raster. What works in favor of this is that there are not many areas with very detailed mapping close to the Equator where the map resolution is web mercator projection is lowest. The disadvantage of this method is of course that a z=12 raster of the whole world is huge so this takes quite some time even if there is only little data. On the other hand this approach copes well with very large amounts of data. My current processing uses method 2 for the Americas and method 1 for the rest of the world. Combining both methods seamlessly is a bit of a problem, therefore this broad division.
From this initial rasterization I generate a pre-simplified river network. In case of method 2 this is further processed and rasterized again at z=9. From the z=9 raster I generate both an area mask and a river network - the former is preserved for later generalization, the latter is analyzed to determine the river importances. As explained in the first part this is the key step of the whole process and while the whole raster processing is being performed in tiles this network analysis needs to be done for the whole planet together. Doing this on the original waterway data from Openstreetmap would not be possible due to the data sizes and the various errors in the data. The river network analysis obviously is very sensitive to any gaps, misoriented river segments and similar problems. The whole purpose of preprocessing with regards to the line features was to generate a consistent and unified global data set with structural errors fixed as much as possible.
Some specific problems
There are a number of problems that occur when applying the process described above to the Openstreetmap data. I will describe some of them in more detail here.
stream selection
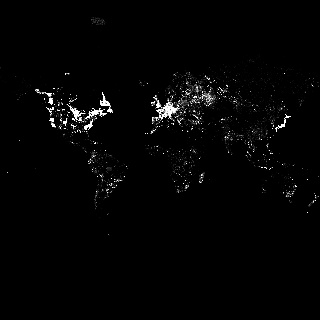
As i have explained in my text on the data quality the classification waterway=stream/river for small/large waterways is of limited use when interpreting the data. Simply ignoring all streams will loose a significant number of waterways important even at low zoom levels and including all will lead to excessive waterway density. The solution i use is removing the streams based on a waterway density map in areas with high density.
|

|
| waterway density | stream removal mask |
River system connections across watershed boundaries
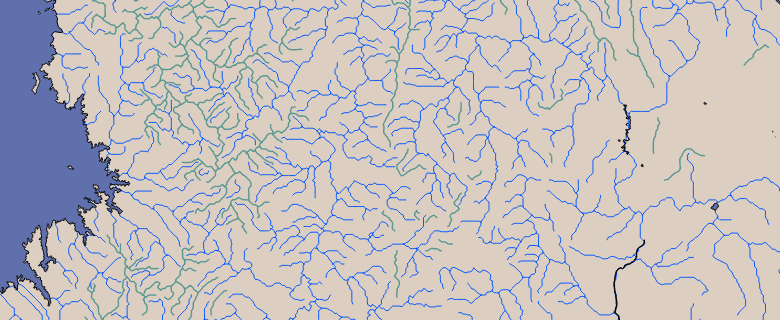
One purpose of the processing described is to bridge narrow gaps in the river system resulting from small errors in the data. This however has the unintended effect of also connecting waterbodies which should be separate. To avoid this approximate watershed boundaries are determined from an elevation model. This only works reliably in mountain areas with sufficiently large elevation differences. Waterways are cut at the boundaries as illustrated below.

|
| watershed boundaries with original waterways (area in Africa east of Lake Kivu) |
|
| watershed boundaries with presimplified and clipped waterways |
As said this only works in steep mountain areas and several faulty connections between river systems in the Openstreetmap data are not caught by this.
Artificial waterways
Artificial waterways, i.e canals, should not be part of this process since they create artificial connections were there would be none with only natural waterflow. Unfortunately tagging of canals as practiced in Openstreetmap is not consistent with this goal. Parts of natural rivers which have been straightened or otherwise significantly modified are frequently tagged as canals while the riverbank areas of canals very often have no specification water=canal. The first problem is addressed by ignoring waterways tagged canal except for those which are part of a waterway relation with tag waterway=river. There is no easy solution for the second problem except adding the relevant tags to the data.
The next part will cover the analysis of the simplified river network to determine the importances of the different rivers and generate the information required for selecting the rivers to be displayed.

Visitor comments:
no comments yet.
By submitting your comment you agree to the privacy policy and agree to the information you provide (except for the email address) to be published on this website.